
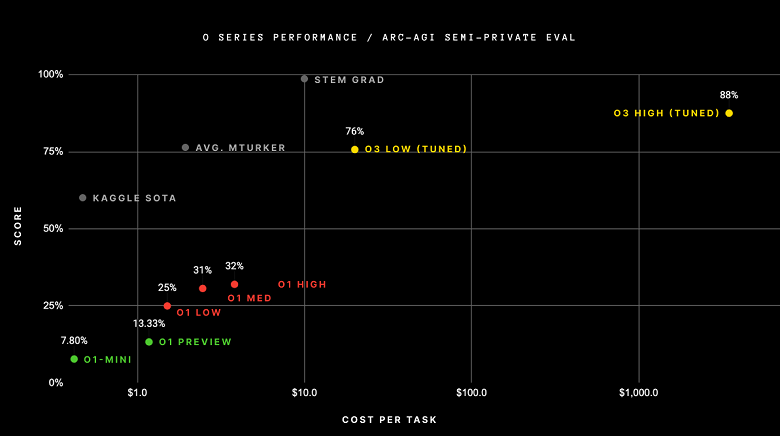
Новая модель OpenAI, o3, достигла беспрецедентного успеха, набрав 75,7% в сложном тесте ARC-AGI в стандартных вычислительных условиях, а в высокопроизводительной версии — 87,5%. Этот результат удивил исследовательское сообщество ИИ, поскольку тест ARC-AGI основан на корпусе абстрактного мышления (Summary Reasoning Corpus), который проверяет способность системы ИИ адаптироваться к новым задачам и демонстрировать «гибкий интеллект». Тест ARC состоит из набора визуальных головоломок, требующих понимания базовых концепций, таких как объекты, границы и пространственные отношения. Хотя люди могут легко решить эти головоломки, нынешние системы ИИ испытывают трудности. ARC долгое время считался одной из самых сложных мер оценки ИИ.
Тест ARC-AGI включает публичные тренировочные и оценочные наборы данных, а также частные и получастные тестовые наборы, которые не разглашаются публично. Это гарантирует, что системы ИИ не могут быть «обмануты» путём обучения на миллионах примеров в надежде охватить все возможные комбинации головоломок. Кроме того, соревнование устанавливает ограничения на объём вычислений, которые участники могут использовать, чтобы гарантировать, что головоломки не решаются методом «грубой силы».

Ранее модели o1-preview и o1 достигли максимального результата в 32% в тесте ARC-AGI. Другой метод, разработанный исследователем Джереми Берманом, использовал гибридный подход, сочетающий Claude 3.5 Sonnet с генетическими алгоритмами и интерпретатором кода, чтобы достичь Fifty three%, что было самым высоким результатом до o3.
Франсуа Шолле, создатель ARC, описал результаты o3 как «удивительный и важный скачок в возможностях ИИ, демонстрирующий способность адаптации к новым задачам, никогда ранее не наблюдаемую в моделях семейства GPT». Он также отметил, что использование большего объёма вычислений на предыдущих поколениях моделей не могло привести к таким результатам.
Однако успех o3 в тесте ARC-AGI достигается за счёт значительных затрат. В низкопроизводительной конфигурации модель тратит от $17 до $20 и 33 миллиона токенов на решение каждой головоломки, в то время как в высокопроизводительной конфигурации модель использует примерно в 172 раза больше вычислительных ресурсов и миллиарды токенов на каждую задачу.
Ключом к решению новых задач, по мнению Шолле и других учёных, является «синтез программ». «Мыслящая» система должна быть способна разрабатывать небольшие программы для решения очень специфических проблем, а затем объединять эти программы для решения более сложных задач. Классические языковые модели поглотили много знаний и содержат богатый набор внутренних программ, но им не хватает композиционности, что мешает решать головоломки, выходящие за рамки обучающей выборки.

При этом, информации о том, как работает o3, очень мало, и здесь мнения учёных расходятся. Шолле предполагает, что o3 использует тип синтеза программ, который использует рассуждения с цепочкой мыслей (CoT) и механизм поиска в сочетании с моделью вознаграждения, которая оценивает и уточняет решения по мере генерации токенов моделью. Это похоже на то, что модели рассуждений с открытым исходным кодом изучали в последние несколько месяцев.
Другие учёные, такие как Натан Ламберт из Института искусственного интеллекта Аллена, предполагают, что «o1 и o3 могут фактически быть просто прямыми проходами из одной языковой модели». В день объявления o3 Нат МакАлис, исследователь из OpenAI, написал в X, что o1 был «просто LLM, обученным с помощью RL. o3 работает на основе дальнейшего масштабирования RL за пределами o1».
В тот же день Денни Чжоу из команды рассуждений Google DeepMind назвал комбинацию поиска и текущих подходов к обучению с подкреплением «тупиком». «Самое прекрасное в рассуждениях LLM заключается в том, что процесс мышления генерируется авторегрессивным способом, а не зависит от поиска (например, mcts) в пространстве генерации, будь то хорошо настроенная модель или тщательно разработанная подсказка», — написал он в X.
Хотя детали того, как o3 рассуждает, могут показаться незначительными по сравнению с прорывом в ARC-AGI, они могут очень хорошо определить следующий сдвиг парадигмы в обучении LLM-моделей. В настоящее время ведутся споры о том, достигли ли законы масштабирования LLM путём обучения данным и вычислений предела. То, зависит ли масштабирование во время тестирования от лучших обучающих данных или других архитектур вывода, может определить следующий шаг в развитии.
Название ARC-AGI может вводить в заблуждение, — некоторые приравняли его к решению AGI. Однако Шолле подчёркивает, что «ARC-AGI — это не лакмусовая бумажка для AGI. Пройти ARC-AGI не означает достижения AGI, и, фактически, я не думаю, что o3 уже является AGI. o3 по-прежнему не справляется с некоторыми очень простыми задачами, что указывает на фундаментальные различия с человеческим интеллектом».
Более того, он отмечает, что o3 не может автономно изучать эти навыки и полагается на внешние верификаторы во время вывода и рассуждения, помеченные человеком, во время обучения.
Другие учёные указали на недостатки результатов. Например, модель была тонко настроена на тренировочном наборе ARC для достижения результатов. «Модели не нужно много специфической обученности, будь то в самом домене или в каждой конкретной задаче», — пишет учёный Мелани Митчелл.
Чтобы проверить, обладают ли эти модели тем видом абстракции и рассуждений, для измерения которых был создан тест ARC, Митчелл предлагает «посмотреть, могут ли эти системы адаптироваться к вариантам конкретных задач или к задачам рассуждений, использующим те же концепции, но в других доменах, чем ARC.
Шолле и его команда в настоящее время работают над новым тестом, который является сложным для o3, потенциально снижая его оценку до менее 30% даже при высоком вычислительном бюджете. Между тем, люди смогут решить 95% головоломок без какого-либо обучения.


